This paper presents three case studies based on projects undertaken by our organisation in the last year that investigated algorithms and software which, either by design or coincidence, have had a notable effect on user’s understandings of both the digital sphere and the offline world, and changed the way they understand and navigate them.
Abstract
This paper presents three case studies based on projects undertaken by our organisation in the last year that investigated algorithms and software which, either by design or coincidence, have had a notable effect on user’s understandings of both the digital sphere and the offline world, and changed the way they understand and navigate them. This is analysed drawing on socio-psychological and philosophical lenses, considering changes in users’ subjective realities. The paper utilises perspectives opened up by recent thought in the fields of Interdisciplinary Posthumanities, Philosophy of Science, and Object Oriented Ontological and Speculative Realist Philosophy. It identifies and conceptualises a new agent of reality formation and individualised identity-construction, one we call the Guru Code. We suggest, from our experience with these recent projects, that Algorithmic AI is a new, creative actor in the field of online identity-construction. Guru Codes have the capacity to responsively alter or reify subjective realities through their entanglement with human users, in ways that were not possible before the introduction of sophisticated Machine Learning algorithms. Moreover, we suggest that these Guru Codes operate between human and machine perception-worlds, environments that function on very different principles; these form a constitutive miscommunication and misapprehension about what is happening, which counterintuitively contribute to its effectiveness.
Introduction
We first look at a commercial project in which we were asked to reify the experience and skills of a client Public Relations company through designing metrics to quantify the social media strategies they deploy on behalf of their clients which were then manipulated into a composite index to create a scoring system – the Social Media Index (SMI) – by which clients (both real and potential) could be invited to compete with each other. Next we analyse the results of our research around YouTube recommendations algorithm; although our interest is not in exposing any proposed bias to the recommendations, we are concerned with the implications of the belief that there might be.
Finally we summarise work undertaken with the Oxford Internet Institute to evaluate the effects of claimed changes to the Facebook newsfeed algorithm on “legacy” and “junk” publishers.
As outsiders to computational creativity, we submit that the following observations should be considered:
1) The experience of the SMI project was as much about those people being worked on by the technology as it was the technology being worked on by them.
2) That, in the course of their being used, the systems are themselves absorbed into their ecosystem such that they both contribute to and reify understanding and practices that eventually can only exist because of the contributions by these computational systems.
3) That the consumption of what is created, whether we agree it is by machine or hybrid, represents real cultural work.
In undertaking commercial work, especially in being invited to projects where our clients perceive Artificial Intelligence as the panacea to their strategic ills, we often come up against the idea that whatever we are about to develop (or propose to develop) is the robotic or software translation of the professional worker into code. On the one hand this seemingly closes down the routes to accepting significant computational endeavours as creative because the assumption is that any product is the invention of either the programmer or the professional he sought to emulate. However, the reverse position is often met with equally robust skepticism.
How does the geologist feel, for example, when told that she is entirely correct that the algorithm demonstrated to her doesn’t share her depth of understanding of the relationship between different chemical compositions and the fasces she decides they belong to and, moreover, it doesn’t need to and is in fact entirely indifferent to the geological theory? Isn’t that removing exactly the techne that permits her creativity?
Another belief we regularly encounter is that in which the entirety of a software system, its outputs and ramifications are under the control of its creators. Either in that they specifically programmed those outcomes or desired those results and that someone, somewhere, is entirely aware of how the software works. This leads to the idea (somewhat strange in our view) that there should be someone to be held responsible if an algorithm on some such platform.
To summarise, clients are unhappy with the idea of us trying to replicate them in code, and equally unhappy when we say we are not trying to code a version of them. Clients have a deep belief in the primacy of human agency and (unsurprisingly) an entirely anthropocentric perspective, but the algorithm we script possesses an entirely unhuman intelligence and makes decisions independently of direct human control. How do we respond to these contradictions? What kinds of interventions do we believe these algorithms make, and how do they operate?
Social Media Index
We were employed by a social agency to produce a Social Media Index (SMI) that ranked companies according to metrics we developed with this client. This was aimed at large, multinational companies operating in many markets for whom the use and practice of social media is (for many reasons) essential. On an individual level, we assumed that the SMI would be developed for heads of digital, communications strategists and other levels of senior management.
Metrics: Aims and Methodology
Metrics were devised over a series of workshops in which practitioners with no experience of data handling or processing were asked to share the experiences of social media use with us. We then turned the anecdotes, strategies and theories they shared with us into metrics from which the efforts of their clients could be assessed. It was defined as important that the Index measured culturally relevant meanings reflective of our client’s values, such as interaction with socially engaged causes, as well as more traditional metrics of organisational success, such as number of followers on Twitter, Glassdoor reviews or Universum score. Metrics tested included a strategy the practitioners called dialogue, which measured the extent to which two-way communication involving an organisation’s social media accounts contained messages on their behalf in the form of questions; the frequency with which social media the accounts in question preceded or followed the median in a time-distribution of hashtag usage; time taken to respond to queries, as a test of the company’s agility.
The SMI aims to frame the perception of markets and the value of the work of social media through lenses the client is confident focus on its strengths. Key to this project was that the SMI be seen to be imparting the client’s subjective values to the Market, perhaps even as much as it is objectively recording performance, and that the client decided on ‘success metrics’ that they felt would appropriately describe their values. However, data that was most ‘saleable’ defined entire lenses according to what was most interesting to talk about; while, conversely, things that could not easily be measured or hard to combine into a wider composite index were dropped. It is also important that the algorithm is tweaked at opportune moments to encourage subscribed companies’ progression up the index, similar to the way in which Google’s search rankings work.
Reflection
Despite their simple and often contested nature, there is growing evidence to suggest that rankings play an enhanced role in decision-making. In their discussion of the global league tables of cities Kornberger and Carter (2010) suggest that league tables are “engines and not simply cameras” that create comparisons between hitherto unrelated places. The resulting competition between global cities is not a natural fact, but it has been brought into being through the circulation of rankings. League tables now, in their words, ‘‘form the battleground on which cities compete with each other’’. Rankings do more than simply grade or describe: they also offer new interpretations of a situation. Actors then adapt their behaviour to conform with this altered understanding. It has also been demonstrated that Identity Dissonance in which a subject is presented with a ranking with which they disagree is a substantial motivator for action. Successful ranking systems and metrics are also those which, while giving the impression (either rightly or wrongly) that movement up and down the scale is possible, also appropriately enforces a hierarchy such that a good score is meaningful and desired.
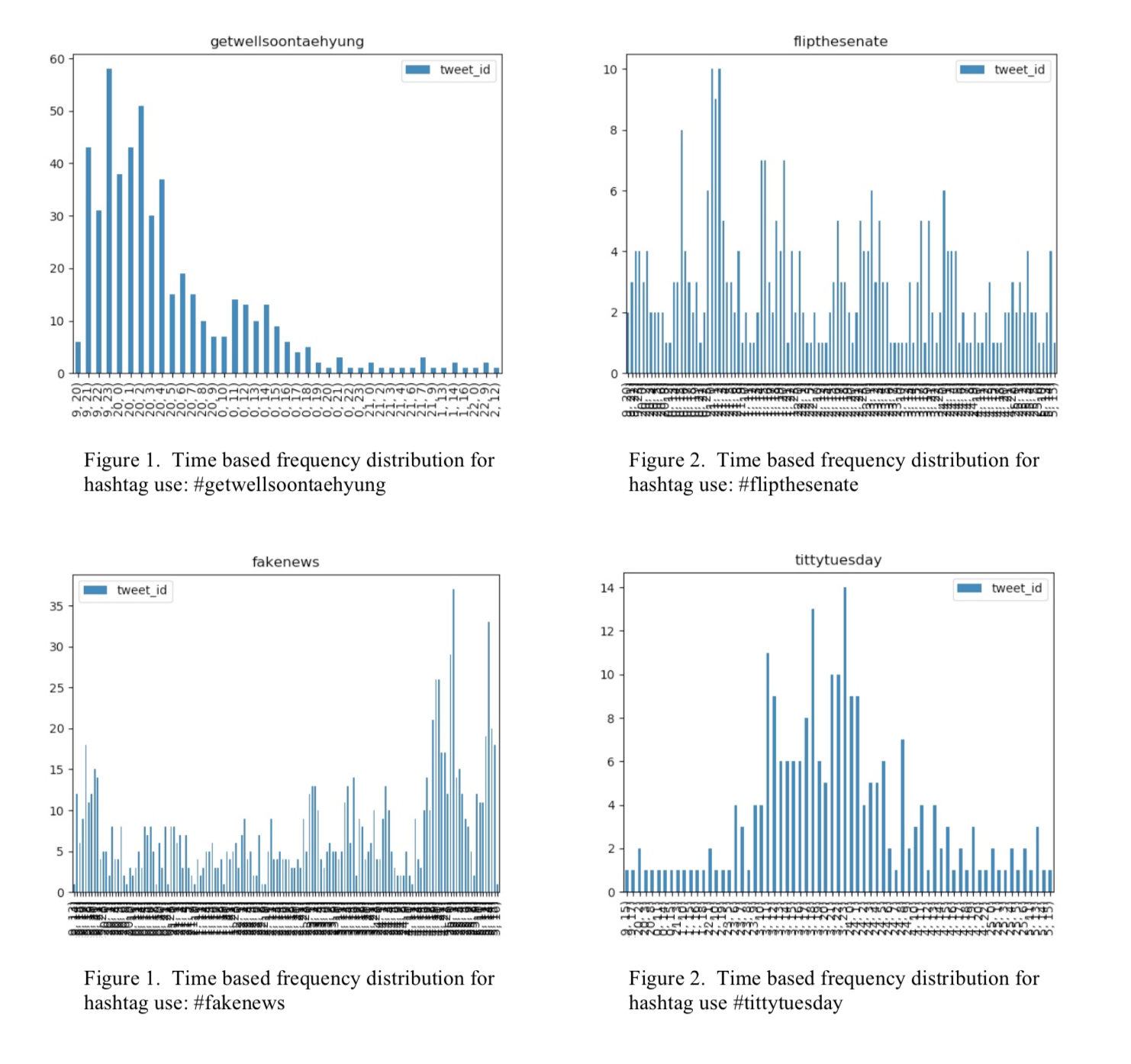
Many of these metrics were and will be subject to revision after deployment. This is not just a response to the testing of the technology and analysis but also a product of the system actually being able to review its data. For example, when defining time based frequency distributions for hashtag use, it quickly became apparent that, far from being simple bell-curves, hashtags could reveal many different distribution types during their life cycles (see figures 1-4 below) and these distributions changed the interpretation of positions relative to the quartiles. A hashtag that was cyclical in nature should be treated as having lifecycles with many median points throughout a month’s sample. Hashtags with tall, thin peaks had gone viral and were thus much quicker to gain value in the ascendent half and lose it in the descendant part.
Overall, results produced were often not those expected by the client, who had assumed a strong and intuitive knowledge of the sector based on their long experience. The algorithm very quickly, in fact, ‘knew’ more about social media influence than the client. The client’s role lay in providing the perspective from which the data was gathered and interpreted, from their (correct or not) intuitive understanding of the arena. The iteratively responsive metrics produced by the algorithm then turned that perspective into the ground of the truth, altering or reifying the subjective realities of participating users, while creating social media gurus out of the client. Similarly, this can impact responsively and reiteratively on users’ identity construction. There have been studies of online identity construction since the 90s (Friedman and Schultermandl 2016; Papacharissi 2011; Turkle 1995), but we have entered a new phase of online identity construction mediated by machine learning algorithms. Online identities are now constructed on an ever-shifting ground, the longer-term effects of which are yet to be seen. Algorithms have not been analysed from this perspective of the new form of machine learning algorithmic identity construction; research has tended to focus either on technologies of surveillance or on bias, in relation to algorithmic identities (Cheney-Lippold 2017; Eubanks 2018; Noble 2018; O’Neill 2016; Zuboff 2019).
The choice of metrics almost invisibly set the terms of engagement for other companies with our client. In effect, the SMI algorithm brought into being a digital world that conformed with their requirements to be able to measure, analyse and sell the analysis to their clients. This could be seen as a form of propaganda in its selective presentation, the way it encourages a particular synthesis or perception, and exerts influence with respect to a specific agenda. It could also, however, be viewed as guru behavior.
Creativity and the Guru Code
The algorithm as Guru Code creates new subjective realities, reshaping and framing markets. Like any futures market or guru, this operates largely on belief in a brand or cult leader’s mastery of knowledge, expertise, charisma and capacity to influence. Gurus provide spiritual guidance enabling followers to realise their ‘true nature’; followers’ prior ideas about this true nature may well be predicated on what they expect from the guru’s teachings, or ways they wish to selectively (re)construct their identities. The Guru Code was produced by the client’s values and strengths, and in turn it has extended and given meaning to the client’s intuitive knowledge of the market. The Code generates a distributed Guru: it turns the client into a charismatic leader, while functioning as the client’s own ‘spiritual guide’. Here, it produces a reality that may be partially pre-empted in our client’s offerings, and partially based on what is easily metricised; it then adapts its response to its findings and interactions.
YouTube
We recently undertook a basic enquiry into the state space of Google videos and the recommendations algorithm for discovering new content. Initial results suggest that the recommendation algorithm does privilege some type of videos over others. For example, while investigating YouTube’s recommendation algorithm, we noticed Canadian Professor of Psychology, self-help author and minor celebrity Jordan Peterson’s name coming up again and again. While he doesn’t usually appear in the “up next” area for music videos or snooker highlights, for any videos about politics, religion, society, gender, philosophy or psychology he’s rarely more than a few clicks away. Based on his subscriber count (he is only the 5,635th most popular by subscriber count), this was puzzling. Peterson became famous in 2016 after vocally opposing Canadian legislation prohibiting discrimination on the grounds of “gender identity or expression”. He has been connected by some with the alt-right, although he identifies politically with Classic Liberalism. He achieved notoriety in the UK for a heated interview with Channel 4 News’ famously tough interviewer Cathy Newman, where his classic liberal individualist views clashed with Newman’s feminist contemporary identity politics position. The frequency with which YouTube recommends videos featuring Peterson has allowed his ideas to spread, creating something of a viral sensation. There are subcultures dedicated to the man and his teachings, where his fans (sometimes referring to themselves as “Lobsters”) identify with his ideas with a passion more usually reserved for sports teams.
Reflection
Superficially, paranoidly, or just anthropocentrically, this could be viewed as a case of right-wing propagandistic promotion. But from an algorithmic perspective there may be something very different going on. Is there a Jordan Peterson Guru Code operation occurring here? To start to address this question, we will digress slightly to ask, what constitutes a computational or machinic algorithmic perception-world? How is it different from human perception-worlds?
As Steven Shaviro states (after Bergson), “Our perceptions… tend to be limited, partial, and self – interested.” ie. we perceive what helps/is useful us, in ways we have evolved to best succeed in our environment (Shaviro 2016). These in turn shape our environment, they form our experience-worlds. To give an example we take a further slight detour, this time into an animal environment. Fish, which hunt fast-moving prey, experience their environment as if in slow motion when measured by human perception of time. Their vision perceives at the equivalent of thirty frames per second rather than the human eighteen; so a fish moment is one thirtieth of a second, while human moments are one eighteenth of a second (Uexkull 2010). Computational algorithmic time is even faster: high frequency trading, for example, takes place at speeds entirely beyond human capacity to comprehend, with computational moments measuring infinitessimal fractions of seconds.
Algorithms operate opaquely, within black boxes. We suggest that these Guru Codes operate between human and machine perception-worlds, and that there is a miscommunication based on a lack of recognition of differing interests. A machinic environment is “entirely abstract, as it consists only in ‘complex fields of data’” (Shaviro 2016).
It does not have an embodied perspective, or affective or emotional understandings of the data and its implications. The assumption of users about the programmed rules, based on the outcome they see and their intuition about human behaviour, ignores fundamental differences between machine and human perception. There is a human assumption that because the code has been programmed to follow rules set by humans, its methods and outputs correspond to human objectives and perspectives, as demonstrated by the SMI project above.
From our research and testing by reverse engineering the algorithm to recreate and examine it, we do NOT believe it is an express purpose of Google to favour particular videos with the YouTube platform. It preferences behaviours rather than content – specifically, it gives preference to videos that tend to lead to people watching more videos. On top of that, the reason people seem to spend so much time on Junk News and the wider community’s videos is because there is ready access to material and content that they already want to hear.
That is to say, YouTube doesn’t act to privilege individuals, but to privilege the community around them because of the behaviours they exhibit in being consumers of their content. Specific types of content generate the behaviours that are rewarded.
We all look at the world and see different things. In YouTube we have found that we now have tools at our disposable for radically reconfirming and solidifying those differences by introducing us to others who share them and then match us with more and more of what we want. The communities that we see emerging on YouTube (and other social media) provide us with a good picture of what it is they need. A strong hierarchy based around family, empathy with animals, the need to feel good about yourself or be good to yourself, attention from others for your thoughts, hopes and dreams – these are needs that are really complex and can be expressed through those sort of activities.
Both in the sense that they’re vulnerable to the ways they come across information but also in that they have real needs that aren’t satisfied by or present in other forms of behaviour, these people are doing real cultural work – making sense of the world. It’s work that needs to be done by all people and what we are finding is that, in the affordance structure of the internet, people can do that for themselves amongst non-hegemonic cultures and across translocal groups. For example, from our research around the online rise of the alt-right in 2016, when we looked at how the alt-right were using reddit and 4chan to organise we watched them ask questions, look for support and develop common practice. Amongst Anti-vaxxers on social media what we find is that they’re commonly looking for confirmation of their world-view without having enough information. A frequent question, especially with an ill child is “Have I done the right thing?” and the unfortunate situation is that it is very easy to find someone who will reply “of course”.
The YouTube Guru Code
Individuals seek identity confirmation through online communities of interest, and traditional concepts of communities are replaced or enhanced by translocal, individualised pick-and-mix identities not based in any fixed context of place, history or culture. Individuals look for groups that confirm and provide a context for their existing beliefs. As James R. Lewis suggests in his study of the 90s Pagan Explosion, “this sort of mediated and mediatized interaction is better described as a form of identity construction” rather than religious conversion (Lewis 2014).
In dynamic systems which make suggestions based on knowledge of people’s interests and preferences, this process is intensified and reified by algorithmic interpretation. The Guru Code carries out programmed rules in ways a human agent employed to make recommendations would not; the Code simply follows its programmed logic absolutely and iteratively, where humans apply intuition, judgement and variation. Algorithms possess an orthogonal, disembodied intelligence completely alien to human
intelligence or the ways in which human think and behave: they operate in an entirely different environment. Stephen Shaviro compares this computational behaviour to Kantian aesthetic gestures of “merely formal purposiveness”, like that of beautiful objects – or the way in which we perceive and interpret them. As Shaviro says of the (fictional) computer system he describes, it “seems ‘purposeful and opaque’, because its activity cannot be entirely ‘explained away’ in terms of its informational function” (Shaviro 2016). This computational causality is not merely the result of following a design; it changes according to its analysis of shifting contexts, and so exceeds its formal purpose, arguably to become an agent of its own purposes.
The speed and translocality of global computation means that people and ideas from across very different cultures and from different historical and political contexts can be suddenly connected. This becomes not only an extremely powerful generator, but also an accelerator of culture when combined with its capability to produce and disseminate material such as Youtube videos instantly on a large scale. The digital machine learning algorithm functions as not only an accelerator of culture, however. As we have seen, both in the Youtube-Jordan Peterson Guru Code and the impact of the alt-right movement on mainstream politics, its reflexive functionality and black box nature enables it to cause reiterative and unpredictable changes to culture based on its findings and interactions. The Guru Code connects people translocally, forming online communities that support their expressed needs and reinforce their existing beliefs.
This is applied globally across cultures, resulting in communities of interest that are not anchored in real-life, in-person or contextual responses. They are based on algorithmic matching of a user’s explicit or extrapolated interests to groups and content that produce certain kinds of behaviour.
The Facebook Newsfeed Algorithm
This case study comes out of a piece of research we worked on for the Oxford Internet Institute. It attempted to quantify the effect of the early-2018 update to the algorithm used by Facebook to populate its user’s newsfeeds on the traffic and reach of publishers who, to a greater or lesser extent, are beholden to Facebook for that traffic. It also explored the way publishers are adapting their strategies in the face of the algorithm changes by studying changing referral rates amongst platforms. We use it here to explore the rhetorical work the term “fake news” does, in the context of the expectations people have for the ability of Facebook to control how its algorithm works and is used, and as another example of the Guru Code at work.
The pressure on Facebook to hold to account “fake news” and spam posts grew throughout 2018 as numerous scandals and accounts of misuse of the platform entered the public sphere. The news generated many questions about the usefulness of Facebook to those interested in spreading misinformation or engaging in political manipulation, and about what is in fact possible. As attention turned in particular to the veracity of information promoted over the platform, Facebook announced multiple changes to the way in which Facebook would choose the information promoted in its newsfeeds and on user news feeds, to make it more personal and employ the strength of users’ own social networks and relationships inside which the content being shared was rated. To quote CEO Mark Zuckerberg:
“The first changes you’ll see will be in News Feed, where you can expect to see more from your friends, family and groups.
As we roll this out, you’ll see less public content like posts from businesses, brands, and media. And the public content you see more will be held to the same standard — it should encourage meaningful interactions between people.”
There are some open admissions by the company about the ways in which the algorithm is now more sensitive to behaviour deemed acceptable or not. However, the changes will undoubtably have caused organisations and people who rely on the platform for exposure to reassess their strategy for using the platform, without all the data required to make a decision available from the outset. To that extent, it was predicted that many publishers would see immediate impact to their engagement and traffic with a delayed response to their efforts to mitigate it as they had to learn to cope with the new algorithm.
While reasonably robust as a source of engagement, Facebook has long been known for changing how the platform technology operated, so publishers will have some experience of needing to adapt to changing conditions. We are already aware of publishers’ changing their strategies and, as a report from Niemann Lab (2018) states:
“By the middle of last year, Google Search had surpassed Facebook as the top referrer for publishers in the Parse.ly network, as Facebook referrals continued to drop overall.”
Our primary interest in studying these changes were in the effect on “junk” publishers and organisations using the Facebook platform for spreading misinformation and political manipulation. The News Feed is the centre column of the homepage a Facebook user sees when logged into the website. It is a constantly updating stream of content from people and Pages that the user follows or that, through some decision taken by the algorithm, is determined relevant through a combination of the user’s interactions on Facebook and those of other people in their network. Facebook does not state publicly the composition of the algorithm deciding on user news feeds. There are however multiple press releases in which they discuss changes that are being made and their intended effects. Over the period looked at by this study we identified nine public declarations from Facebook about modifications to the newsfeed algorithm or to the way newsfeeds are intended to work.
Reflection
Our study concluded that, while Facebook is not necessarily honest about what work it does on its algorithm, at face value something happened in 2018 that made it decide that grounding it in the community and family of a user was politically important, as was the concept of “meaningful interactions”, as elaborated in our recent talkReal Friends and Meaningful Interactions ([anonymised] 2018). Superficially, this appeared to be a response to the Cambridge Analytica scandal and the political implications of it. However, we believe it is telling that the decision to ground this response “in communities” sets up the phenomena they were trying to combat as being somehow oppositional to the idea of community. This seems to be a denial of the possibility that community could be produced by algorithm, and at the same time an appeal to some definition of offline community as more natural and thus a more acceptable narrator of acceptable online information gathering. We found that there was a tangible effect on small publishers after the algorithm changes, but not on the larger “legacy” publishers. algorithm or to the way newsfeeds are intended to work.
The Facebook Guru Code
Christakis and Fowler wrote in the preface to their widely cited book on social network analysis:
“the nodes in our networks… can make decisions, potentially changing their networks even while embedded in them and being affected by them.” (2009)
They were referring to human nodes, and this was a description of the specialness of human agents within networks. However, the Guru Code demonstrates the same characteristics, as shown in our analysis of the Facebook algorithm, operating on two levels:
1) The algorithm was directly responsible for editorial strategy and, when it was changed, directly responsible to changes to editorial strategy.
2) The changes came about in response to a (hysterical) conversation about “junk news” etc. that was a product of the algorithm itself. That is, the facebook algorithm created the conditions by which the junk news panic came about, afforded the growth on conversation about it (possibly by allowing peoples’ anxieties to be projected onto it) and was itself the primary driver behind changes in response to the panic.
The Guru Code creatively exerts influence and creativity, even if it doesn’t operate in the same way. And, in fact, it has far more power than any individual human agent due partly to its speed, disembodied tirelessness (it doesn’t need to eat, sleep, rest), and scope; and partly because of its function as a central mediator, broker, and advisor of online interactions.
Conclusion
Algorithmic computation not only speeds up and abstracts human-to-human and human-to-machine interactions, but through its learning capacity it can and does create changes to human culture. Algorithms function as Guru Code when they creatively alter subjective realities or assist in identity construction, and as a result make changes to human culture. We are not suggesting this is due to a super intelligence – an algorithm does not need to be intelligent, or to understand human culture in order to creatively change it. The Guru Code is able to do this because of the way it operates and the ways human respond. It does this in a number of ways.
Guru Codes present new evaluative criteria for being and acting in the world, offering new interpretations of a situation, encouraging a particular synthesis or perception of a situation. They exert influence from a particular perspective that is contextually or implicitly invited by its users, or followers. Based on this, and on constant reflective adaptation from feedback, they offer tailored suggestions and guidance. This allows them to reflexively motivate change. The Guru Code changes human cultures iteratively and translocally, while its ability to create and disseminate on large scale give it the massive reach and influence of an uber-guru. Its lack of understanding and the misapprehension of humans about how it functions contribute to its effectiveness and the extent of change it can produce. As demonstrated by the examples given above, people ascribe human agency to (and human accountability for) algorithmically-generated league tables and recommendations that in fact generally only have human input at the beginning.
Subsequently, the Code evolves based on evaluation, metrics and iterative feedback autonomously of humans and in ways that are entirely un-human. Algorithmic judgement functions entirely differently from human processes of discrimination. Humans balance logic with other forms of knowledge: they apply embodied intuition and instinct, and respond to contextual or affective knowledge in nuanced ways that a machine does not.
Computational creativity research, as we understand it, is keen to explore how and to what extent computers can be involved in contributing to human culture and innovation. We believe we are scratching the surface of exploring how computers and algorithms are beginning to marshal humans in the service of a culture that emerges from computation.
References
Friedman, May, Silvia Schultermandl, and Laura E En- riquez. Click and Kin: Transnational Identity and Quick Media, 2016.
“Has Facebook’s Algorithm Change Hurt Hyperpartisan Sites? According to This Data, Nope.” Nieman Lab (blog). Accessed February 26, 2019.
Cheney-Lippold, John. We Are Data: Algorithms and the Making of Our Digital Selves. New York: New York University Press, 2017.
Kornberger, Martin, and Chris Carter. “Manufacturing Competition: How Accounting Practices Shape Strategy Making in Cities.” Accounting, Auditing & Accountability Journal 23, no. 3 (2010): 325–349.
Lewis, James. “Becoming a Virtual Pagan: ‘Conversion’ or Identity Construction?” POME Pomegranate: The International Journal of Pagan Studies 16, no. 1 (2014): 24–34.
Nicholas A. Christakis. Connected: The Amazing Power of Social Networks and How They Shape Our Lives. Lon- don: HarperPress, 2011.
O’Neil, Cathy. Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy. London: Penguin Books, 2018.
Papacharissi, Zizi. A Networked Self: Identity, Community, and Culture on Social Network Sites. Routledge Ltd, 2010.
Safiya Umoja Noble. Algorithms of Oppression: How Search Engines Reinforce Racism. New York: New York University Press, 2018.
Shaviro, Steven. Discognition. London: Repeater, 2016.
Sherry. Turkle. Life on the Screen: Identity in the Age of the Internet. New York: Simon & Schuster, 1995.
Uexküll, Jakob von. A Foray into the Worlds of Animals and Humans: With A Theory of Meaning. Minneapolis: University of Minnesota Press, 2010.
Virginia Eubanks. Automating Inequality: How High- Tech Tools Profile, Police, and Punish the Poor. New York, NY: St Martin’s Press, 2017.
Zuboff, Shoshana. The age of surveillance capitalism: the fight for a human future at the new frontier of power, 2019.